 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Anomaly Detection
Papers and Code
DMS2F-HAD: A Dual-branch Mamba-based Spatial-Spectral Fusion Network for Hyperspectral Anomaly Detection
Feb 04, 2026Hyperspectral anomaly detection (HAD) aims to identify rare and irregular targets in high-dimensional hyperspectral images (HSIs), which are often noisy and unlabelled data. Existing deep learning methods either fail to capture long-range spectral dependencies (e.g., convolutional neural networks) or suffer from high computational cost (e.g., Transformers). To address these challenges, we propose DMS2F-HAD, a novel dual-branch Mamba-based model. Our architecture utilizes Mamba's linear-time modeling to efficiently learn distinct spatial and spectral features in specialized branches, which are then integrated by a dynamic gated fusion mechanism to enhance anomaly localization. Across fourteen benchmark HSI datasets, our proposed DMS2F-HAD not only achieves a state-of-the-art average AUC of 98.78%, but also demonstrates superior efficiency with an inference speed 4.6 times faster than comparable deep learning methods. The results highlight DMS2FHAD's strong generalization and scalability, positioning it as a strong candidate for practical HAD applications.
Utilizing the Score of Data Distribution for Hyperspectral Anomaly Detection
Jan 18, 2026Hyperspectral images (HSIs) are a type of image that contains abundant spectral information. As a type of real-world data, the high-dimensional spectra in hyperspectral images are actually determined by only a few factors, such as chemical composition and illumination. Thus, spectra in hyperspectral images are highly likely to satisfy the manifold hypothesis. Based on the hyperspectral manifold hypothesis, we propose a novel hyperspectral anomaly detection method (named ScoreAD) that leverages the time-dependent gradient field of the data distribution (i.e., the score), as learned by a score-based generative model (SGM). Our method first trains the SGM on the entire set of spectra from the hyperspectral image. At test time, each spectrum is passed through a perturbation kernel, and the resulting perturbed spectrum is fed into the trained SGM to obtain the estimated score. The manifold hypothesis of HSIs posits that background spectra reside on one or more low-dimensional manifolds. Conversely, anomalous spectra, owing to their unique spectral signatures, are considered outliers that do not conform to the background manifold. Based on this fundamental discrepancy in their manifold distributions, we leverage a generative SGM to achieve hyperspectral anomaly detection. Experiments on the four hyperspectral datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/jiahuisheng/ScoreAD.
Turbo-GoDec: Exploiting the Cluster Sparsity Prior for Hyperspectral Anomaly Detection
Jan 18, 2026As a key task in hyperspectral image processing, hyperspectral anomaly detection has garnered significant attention and undergone extensive research. Existing methods primarily relt on two prior assumption: low-rank background and sparse anomaly, along with additional spatial assumptions of the background. However, most methods only utilize the sparsity prior assumption for anomalies and rarely expand on this hypothesis. From observations of hyperspectral images, we find that anomalous pixels exhibit certain spatial distribution characteristics: they often manifest as small, clustered groups in space, which we refer to as cluster sparsity of anomalies. Then, we combined the cluster sparsity prior with the classical GoDec algorithm, incorporating the cluster sparsity prior into the S-step of GoDec. This resulted in a new hyperspectral anomaly detection method, which we called Turbo-GoDec. In this approach, we modeled the cluster sparsity prior of anomalies using a Markov random field and computed the marginal probabilities of anomalies through message passing on a factor graph. Locations with high anomalous probabilities were treated as the sparse component in the Turbo-GoDec. Experiments are conducted on three real hyperspectral image (HSI) datasets which demonstrate the superior performance of the proposed Turbo-GoDec method in detecting small-size anomalies comparing with the vanilla GoDec (LSMAD) and state-of-the-art anomaly detection methods. The code is available at https://github.com/jiahuisheng/Turbo-GoDec.
Mitigating Long-Tailed Anomaly Score Distributions with Importance-Weighted Loss
Jan 05, 2026Anomaly detection is crucial in industrial applications for identifying rare and unseen patterns to ensure system reliability. Traditional models, trained on a single class of normal data, struggle with real-world distributions where normal data exhibit diverse patterns, leading to class imbalance and long-tailed anomaly score distributions (LTD). This imbalance skews model training and degrades detection performance, especially for minority instances. To address this issue, we propose a novel importance-weighted loss designed specifically for anomaly detection. Compared to the previous method for LTD in classification, our method does not require prior knowledge of normal data classes. Instead, we introduce a weighted loss function that incorporates importance sampling to align the distribution of anomaly scores with a target Gaussian, ensuring a balanced representation of normal data. Extensive experiments on three benchmark image datasets and three real-world hyperspectral imaging datasets demonstrate the robustness of our approach in mitigating LTD-induced bias. Our method improves anomaly detection performance by 0.043, highlighting its effectiveness in real-world applications.
* 8 pages, Published as a conference paper at IJCNN 2025
Hyperspectral Anomaly Detection Fused Unified Nonconvex Tensor Ring Factors Regularization
May 23, 2025In recent years, tensor decomposition-based approaches for hyperspectral anomaly detection (HAD) have gained significant attention in the field of remote sensing. However, existing methods often fail to fully leverage both the global correlations and local smoothness of the background components in hyperspectral images (HSIs), which exist in both the spectral and spatial domains. This limitation results in suboptimal detection performance. To mitigate this critical issue, we put forward a novel HAD method named HAD-EUNTRFR, which incorporates an enhanced unified nonconvex tensor ring (TR) factors regularization. In the HAD-EUNTRFR framework, the raw HSIs are first decomposed into background and anomaly components. The TR decomposition is then employed to capture the spatial-spectral correlations within the background component. Additionally, we introduce a unified and efficient nonconvex regularizer, induced by tensor singular value decomposition (TSVD), to simultaneously encode the low-rankness and sparsity of the 3-D gradient TR factors into a unique concise form. The above characterization scheme enables the interpretable gradient TR factors to inherit the low-rankness and smoothness of the original background. To further enhance anomaly detection, we design a generalized nonconvex regularization term to exploit the group sparsity of the anomaly component. To solve the resulting doubly nonconvex model, we develop a highly efficient optimization algorithm based on the alternating direction method of multipliers (ADMM) framework. Experimental results on several benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art (SOTA) approaches in terms of detection accuracy.
CL-BioGAN: Biologically-Inspired Cross-Domain Continual Learning for Hyperspectral Anomaly Detection
May 17, 2025Memory stability and learning flexibility in continual learning (CL) is a core challenge for cross-scene Hyperspectral Anomaly Detection (HAD) task. Biological neural networks can actively forget history knowledge that conflicts with the learning of new experiences by regulating learning-triggered synaptic expansion and synaptic convergence. Inspired by this phenomenon, we propose a novel Biologically-Inspired Continual Learning Generative Adversarial Network (CL-BioGAN) for augmenting continuous distribution fitting ability for cross-domain HAD task, where Continual Learning Bio-inspired Loss (CL-Bio Loss) and self-attention Generative Adversarial Network (BioGAN) are incorporated to realize forgetting history knowledge as well as involving replay strategy in the proposed BioGAN. Specifically, a novel Bio-Inspired Loss composed with an Active Forgetting Loss (AF Loss) and a CL loss is designed to realize parameters releasing and enhancing between new task and history tasks from a Bayesian perspective. Meanwhile, BioGAN loss with L2-Norm enhances self-attention (SA) to further balance the stability and flexibility for better fitting background distribution for open scenario HAD (OHAD) tasks. Experiment results underscore that the proposed CL-BioGAN can achieve more robust and satisfying accuracy for cross-domain HAD with fewer parameters and computation cost. This dual contribution not only elevates CL performance but also offers new insights into neural adaptation mechanisms in OHAD task.
CL-CaGAN: Capsule differential adversarial continuous learning for cross-domain hyperspectral anomaly detection
May 17, 2025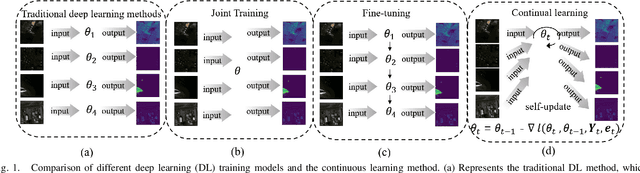
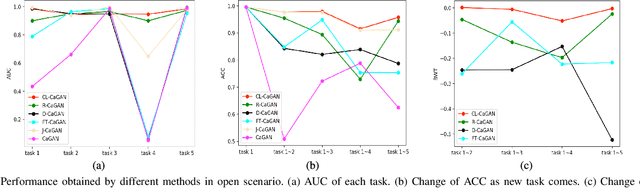
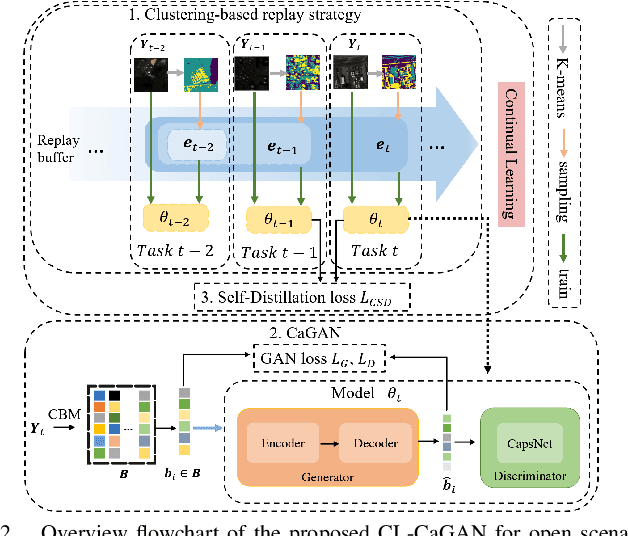
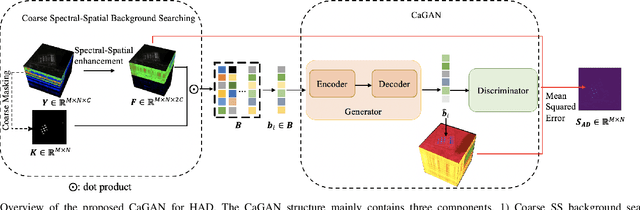
Anomaly detection (AD) has attracted remarkable attention in hyperspectral image (HSI) processing fields, and most existing deep learning (DL)-based algorithms indicate dramatic potential for detecting anomaly samples through specific training process under current scenario. However, the limited prior information and the catastrophic forgetting problem indicate crucial challenges for existing DL structure in open scenarios cross-domain detection. In order to improve the detection performance, a novel continual learning-based capsule differential generative adversarial network (CL-CaGAN) is proposed to elevate the cross-scenario learning performance for facilitating the real application of DL-based structure in hyperspectral AD (HAD) task. First, a modified capsule structure with adversarial learning network is constructed to estimate the background distribution for surmounting the deficiency of prior information. To mitigate the catastrophic forgetting phenomenon, clustering-based sample replay strategy and a designed extra self-distillation regularization are integrated for merging the history and future knowledge in continual AD task, while the discriminative learning ability from previous detection scenario to current scenario is retained by the elaborately designed structure with continual learning (CL) strategy. In addition, the differentiable enhancement is enforced to augment the generation performance of the training data. This further stabilizes the training process with better convergence and efficiently consolidates the reconstruction ability of background samples. To verify the effectiveness of our proposed CL-CaGAN, we conduct experiments on several real HSIs, and the results indicate that the proposed CL-CaGAN demonstrates higher detection performance and continuous learning capacity for mitigating the catastrophic forgetting under cross-domain scenarios.
Overcoming the Identity Mapping Problem in Self-Supervised Hyperspectral Anomaly Detection
Apr 05, 2025The surge of deep learning has catalyzed considerable progress in self-supervised Hyperspectral Anomaly Detection (HAD). The core premise for self-supervised HAD is that anomalous pixels are inherently more challenging to reconstruct, resulting in larger errors compared to the background. However, owing to the powerful nonlinear fitting capabilities of neural networks, self-supervised models often suffer from the Identity Mapping Problem (IMP). The IMP manifests as a tendency for the model to overfit to the entire image, particularly with increasing network complexity or prolonged training iterations. Consequently, the whole image can be precisely reconstructed, and even the anomalous pixels exhibit imperceptible errors, making them difficult to detect. Despite the proposal of several models aimed at addressing the IMP-related issues, a unified descriptive framework and validation of solutions for IMP remain lacking. In this paper, we conduct an in-depth exploration to IMP, and summarize a unified framework that describes IMP from the perspective of network optimization, which encompasses three aspects: perturbation, reconstruction, and regularization. Correspondingly, we introduce three solutions: superpixel pooling and uppooling for perturbation, error-adaptive convolution for reconstruction, and online background pixel mining for regularization. With extensive experiments being conducted to validate the effectiveness, it is hoped that our work will provide valuable insights and inspire further research for self-supervised HAD. Code: \url{https://github.com/yc-cui/Super-AD}.
Spectral-Spatial Extraction through Layered Tensor Decomposition for Hyperspectral Anomaly Detection
Mar 07, 2025Low rank tensor representation (LRTR) methods are very useful for hyperspectral anomaly detection (HAD). To overcome the limitations that they often overlook spectral anomaly and rely on large-scale matrix singular value decomposition, we first apply non-negative matrix factorization (NMF) to alleviate spectral dimensionality redundancy and extract spectral anomaly and then employ LRTR to extract spatial anomaly while mitigating spatial redundancy, yielding a highly efffcient layered tensor decomposition (LTD) framework for HAD. An iterative algorithm based on proximal alternating minimization is developed to solve the proposed LTD model, with convergence guarantees provided. Moreover, we introduce a rank reduction strategy with validation mechanism that adaptively reduces data size while preventing excessive reduction. Theoretically, we rigorously establish the equivalence between the tensor tubal rank and tensor group sparsity regularization (TGSR) and, under mild conditions, demonstrate that the relaxed formulation of TGSR shares the same global minimizers and optimal values as its original counterpart. Experimental results on the Airport-Beach-Urban and MVTec datasets demonstrate that our approach outperforms state-of-the-art methods in the HAD task.
ACMamba: Fast Unsupervised Anomaly Detection via An Asymmetrical Consensus State Space Model
Apr 16, 2025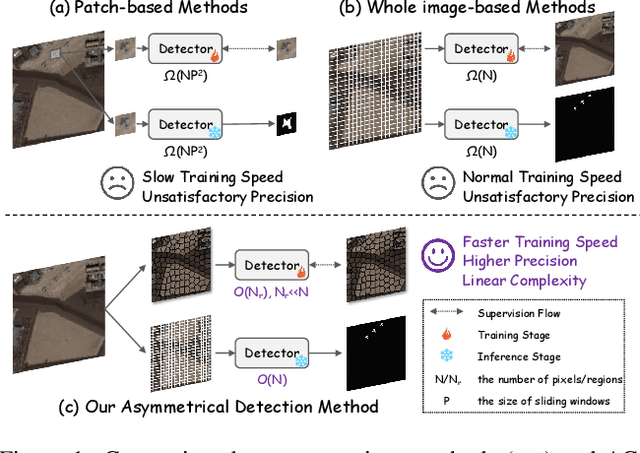
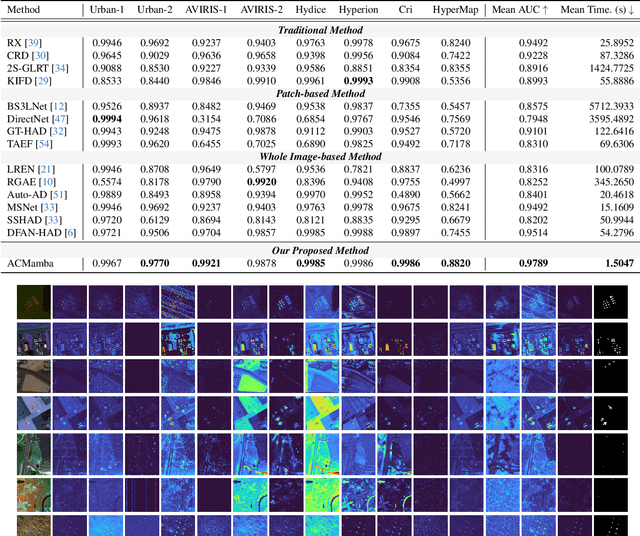
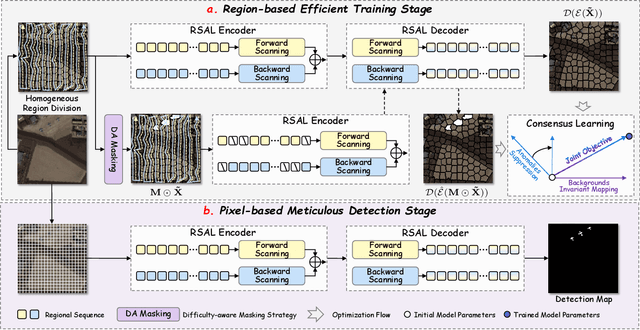
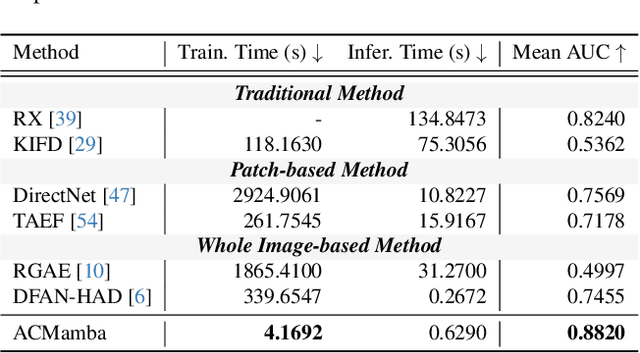
Unsupervised anomaly detection in hyperspectral images (HSI), aiming to detect unknown targets from backgrounds, is challenging for earth surface monitoring. However, current studies are hindered by steep computational costs due to the high-dimensional property of HSI and dense sampling-based training paradigm, constraining their rapid deployment. Our key observation is that, during training, not all samples within the same homogeneous area are indispensable, whereas ingenious sampling can provide a powerful substitute for reducing costs. Motivated by this, we propose an Asymmetrical Consensus State Space Model (ACMamba) to significantly reduce computational costs without compromising accuracy. Specifically, we design an asymmetrical anomaly detection paradigm that utilizes region-level instances as an efficient alternative to dense pixel-level samples. In this paradigm, a low-cost Mamba-based module is introduced to discover global contextual attributes of regions that are essential for HSI reconstruction. Additionally, we develop a consensus learning strategy from the optimization perspective to simultaneously facilitate background reconstruction and anomaly compression, further alleviating the negative impact of anomaly reconstruction. Theoretical analysis and extensive experiments across eight benchmarks verify the superiority of ACMamba, demonstrating a faster speed and stronger performance over the state-of-the-art.